 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical Analysis of Engression and Reverse Markov Engression
May 31, 2026Engression is a recently proposed and effective framework for conditional distribution learning. Its multi-step Reverse Markov extension further improves generative flexibility by decomposing complex conditional sampling into sequential reverse transitions. Despite their strong empirical performance, rigorous finite-sample statistical guarantees for these methods remain unavailable. In this paper, under deep neural network parameterizations, we establish nonasymptotic convergence bounds for Engression by directly controlling the Energy Distance between the learned and target conditional distributions. For the Reverse Markov framework, we further develop an Energy-Distance-based chain rule that enables a rigorous analysis of error propagation across reverse steps. Our analysis yields corresponding excess-risk bounds that are near-optimal up to logarithmic factors relative to the classical minimax rate over a general Hölder class.
Efficient Synthetic Network Generation via Latent Embedding Reconstruction
May 31, 2026Network data are ubiquitous across the social sciences, biology, and information systems. Generating realistic synthetic network data has broad applications from network simulation to scientific discovery. However, many existing black-box approaches for network generation tend to overfit observed data while overlooking characteristic network structure, and incur substantial computational overhead at scale. These practical challenges call for synthetic network generation methods that are both efficient and capable of capturing structural properties of networks. In this paper, we introduce Synthetic Network Generation via Latent Embedding Reconstruction (SyNGLER), a general and efficient framework for synthetic network generation that builds on latent space network models. Given an observed network, SyNGLER first learns low-dimensional latent node embeddings via a latent space network model and then reconstructs the latent space by building a distribution-free generator over these embeddings. For generation, SyNGLER first samples (or resamples) node embeddings from the generator in the latent space and then produces synthetic networks using the latent space network model. Through the latent space framework, SyNGLER preserves unique characteristics in networks such as sparsity and node degree heterogeneity, while allowing for efficient training with lower computational cost than many existing deep architectures. We provide theoretical guarantees by developing consistency results on the distance between the true and synthetic edge distributions. Empirical studies further demonstrate the effectiveness of SyNGLER, which efficiently produces networks that better preserve key network characteristics such as network moments and degree distributions compared with existing approaches. Code is available at https://github.com/FeifanJiang/syngler.
Interpretable Network-assisted Random Forest+
Sep 19, 2025Machine learning algorithms often assume that training samples are independent. When data points are connected by a network, the induced dependency between samples is both a challenge, reducing effective sample size, and an opportunity to improve prediction by leveraging information from network neighbors. Multiple methods taking advantage of this opportunity are now available, but many, including graph neural networks, are not easily interpretable, limiting their usefulness for understanding how a model makes its predictions. Others, such as network-assisted linear regression, are interpretable but often yield substantially worse prediction performance. We bridge this gap by proposing a family of flexible network-assisted models built upon a generalization of random forests (RF+), which achieves highly-competitive prediction accuracy and can be interpreted through feature importance measures. In particular, we develop a suite of interpretation tools that enable practitioners to not only identify important features that drive model predictions, but also quantify the importance of the network contribution to prediction. Importantly, we provide both global and local importance measures as well as sample influence measures to assess the impact of a given observation. This suite of tools broadens the scope and applicability of network-assisted machine learning for high-impact problems where interpretability and transparency are essential.
GSON: A Group-based Social Navigation Framework with Large Multimodal Model
Sep 26, 2024As the number of service robots and autonomous vehicles in human-centered environments grows, their requirements go beyond simply navigating to a destination. They must also take into account dynamic social contexts and ensure respect and comfort for others in shared spaces, which poses significant challenges for perception and planning. In this paper, we present a group-based social navigation framework GSON to enable mobile robots to perceive and exploit the social group of their surroundings by leveling the visual reasoning capability of the Large Multimodal Model (LMM). For perception, we apply visual prompting techniques to zero-shot extract the social relationship among pedestrians and combine the result with a robust pedestrian detection and tracking pipeline to alleviate the problem of low inference speed of the LMM. Given the perception result, the planning system is designed to avoid disrupting the current social structure. We adopt a social structure-based mid-level planner as a bridge between global path planning and local motion planning to preserve the global context and reactive response. The proposed method is validated on real-world mobile robot navigation tasks involving complex social structure understanding and reasoning. Experimental results demonstrate the effectiveness of the system in these scenarios compared with several baselines.
EmbSum: Leveraging the Summarization Capabilities of Large Language Models for Content-Based Recommendations
May 19, 2024Content-based recommendation systems play a crucial role in delivering personalized content to users in the digital world. In this work, we introduce EmbSum, a novel framework that enables offline pre-computations of users and candidate items while capturing the interactions within the user engagement history. By utilizing the pretrained encoder-decoder model and poly-attention layers, EmbSum derives User Poly-Embedding (UPE) and Content Poly-Embedding (CPE) to calculate relevance scores between users and candidate items. EmbSum actively learns the long user engagement histories by generating user-interest summary with supervision from large language model (LLM). The effectiveness of EmbSum is validated on two datasets from different domains, surpassing state-of-the-art (SoTA) methods with higher accuracy and fewer parameters. Additionally, the model's ability to generate summaries of user interests serves as a valuable by-product, enhancing its usefulness for personalized content recommendations.
Minimax Regret Learning for Data with Heterogeneous Subgroups
May 02, 2024Modern complex datasets often consist of various sub-populations. To develop robust and generalizable methods in the presence of sub-population heterogeneity, it is important to guarantee a uniform learning performance instead of an average one. In many applications, prior information is often available on which sub-population or group the data points belong to. Given the observed groups of data, we develop a min-max-regret (MMR) learning framework for general supervised learning, which targets to minimize the worst-group regret. Motivated from the regret-based decision theoretic framework, the proposed MMR is distinguished from the value-based or risk-based robust learning methods in the existing literature. The regret criterion features several robustness and invariance properties simultaneously. In terms of generalizability, we develop the theoretical guarantee for the worst-case regret over a super-population of the meta data, which incorporates the observed sub-populations, their mixtures, as well as other unseen sub-populations that could be approximated by the observed ones. We demonstrate the effectiveness of our method through extensive simulation studies and an application to kidney transplantation data from hundreds of transplant centers.
Fair Information Spread on Social Networks with Community Structure
May 15, 2023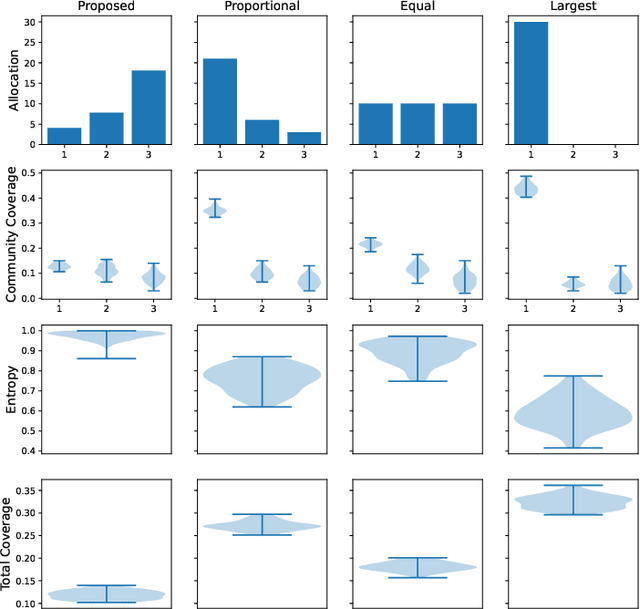
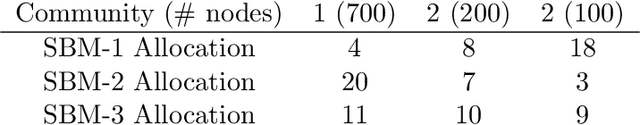
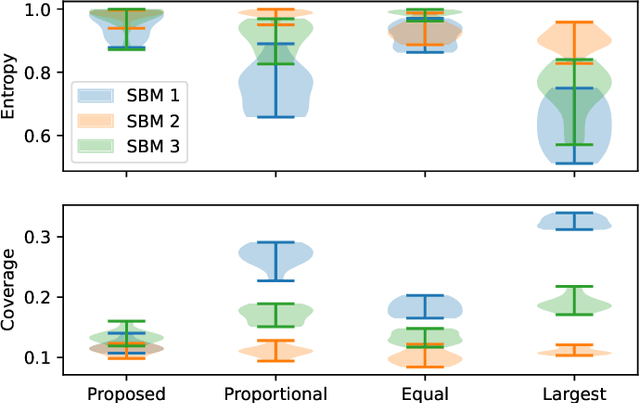

Information spread through social networks is ubiquitous. Influence maximiza- tion (IM) algorithms aim to identify individuals who will generate the greatest spread through the social network if provided with information, and have been largely devel- oped with marketing in mind. In social networks with community structure, which are very common, IM algorithms focused solely on maximizing spread may yield signifi- cant disparities in information coverage between communities, which is problematic in settings such as public health messaging. While some IM algorithms aim to remedy disparity in information coverage using node attributes, none use the empirical com- munity structure within the network itself, which may be beneficial since communities directly affect the spread of information. Further, the use of empirical network struc- ture allows us to leverage community detection techniques, making it possible to run fair-aware algorithms when there are no relevant node attributes available, or when node attributes do not accurately capture network community structure. In contrast to other fair IM algorithms, this work relies on fitting a model to the social network which is then used to determine a seed allocation strategy for optimal fair information spread. We develop an algorithm to determine optimal seed allocations for expected fair coverage, defined through maximum entropy, provide some theoretical guarantees under appropriate conditions, and demonstrate its empirical accuracy on both simu- lated and real networks. Because this algorithm relies on a fitted network model and not on the network directly, it is well-suited for partially observed and noisy social networks.
Conformal Prediction for Network-Assisted Regression
Feb 23, 2023



An important problem in network analysis is predicting a node attribute using both network covariates, such as graph embedding coordinates or local subgraph counts, and conventional node covariates, such as demographic characteristics. While standard regression methods that make use of both types of covariates may be used for prediction, statistical inference is complicated by the fact that the nodal summary statistics are often dependent in complex ways. We show that under a mild joint exchangeability assumption, a network analog of conformal prediction achieves finite sample validity for a wide range of network covariates. We also show that a form of asymptotic conditional validity is achievable. The methods are illustrated on both simulated networks and a citation network dataset.
Variational Estimators of the Degree-corrected Latent Block Model for Bipartite Networks
Jun 16, 2022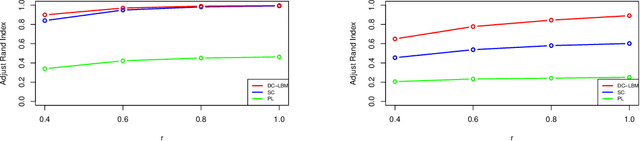
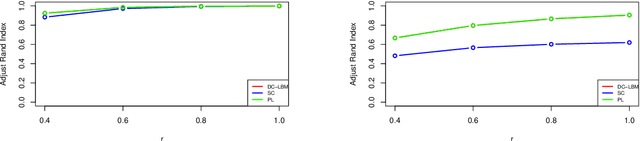


Biclustering on bipartite graphs is an unsupervised learning task that simultaneously clusters the two types of objects in the graph, for example, users and movies in a movie review dataset. The latent block model (LBM) has been proposed as a model-based tool for biclustering. Biclustering results by the LBM are, however, usually dominated by the row and column sums of the data matrix, i.e., degrees. We propose a degree-corrected latent block model (DC-LBM) to accommodate degree heterogeneity in row and column clusters, which greatly outperforms the classical LBM in the MovieLens dataset and simulated data. We develop an efficient variational expectation-maximization algorithm by observing that the row and column degrees maximize the objective function in the M step given any probability assignment on the cluster labels. We prove the label consistency of the variational estimator under the DC-LBM, which allows the expected graph density goes to zero as long as the average expected degrees of rows and columns go to infinity.
Latent space models for multiplex networks with shared structure
Dec 28, 2020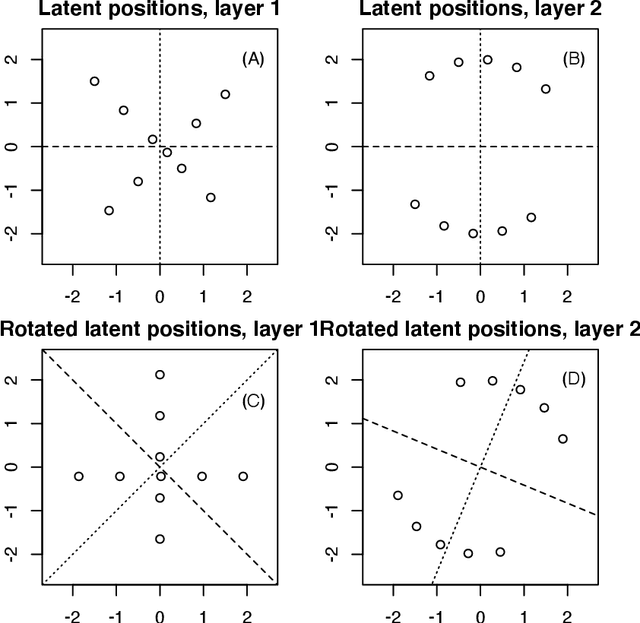
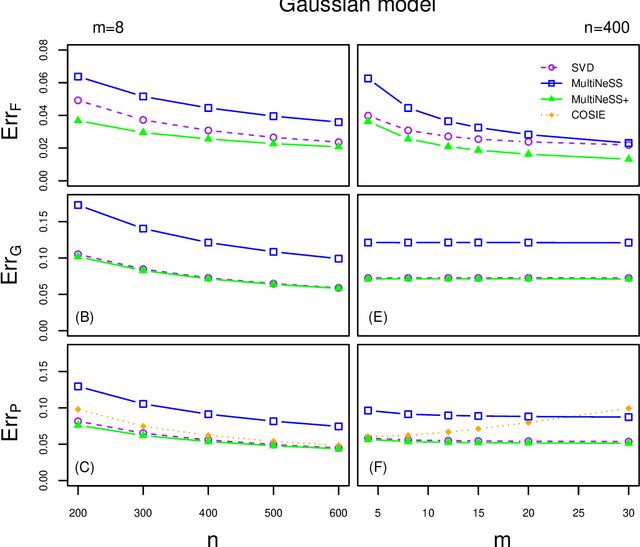
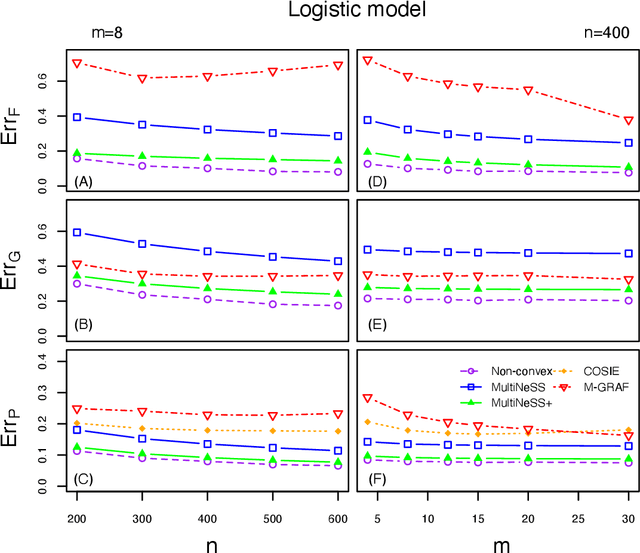
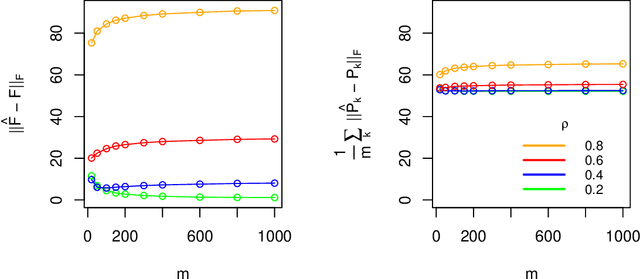
Latent space models are frequently used for modeling single-layer networks and include many popular special cases, such as the stochastic block model and the random dot product graph. However, they are not well-developed for more complex network structures, which are becoming increasingly common in practice. Here we propose a new latent space model for multiplex networks: multiple, heterogeneous networks observed on a shared node set. Multiplex networks can represent a network sample with shared node labels, a network evolving over time, or a network with multiple types of edges. The key feature of our model is that it learns from data how much of the network structure is shared between layers and pools information across layers as appropriate. We establish identifiability, develop a fitting procedure using convex optimization in combination with a nuclear norm penalty, and prove a guarantee of recovery for the latent positions as long as there is sufficient separation between the shared and the individual latent subspaces. We compare the model to competing methods in the literature on simulated networks and on a multiplex network describing the worldwide trade of agricultural products.